유연한 시스템 설계 방법 톺아보기와 자문자답
참고 자료
유연한 시스템이 왜 필요한 것인가?
사용자가 많아지게 되면 서비스를 제공할 수 있는 가용 서버를 늘려 트래픽에 대응할 수 있어야한다.
하지만 어떤 조직이던간에 우리가 사용할 수 있는 자원은 필연적으로 한정되어있다. 따라서 자원을 효율적으로 사용하여 가용할 수 있는 서버를 늘리는 것이 우아하게 사용자의 요구를 처리할 수 있는 방법이다.
그래서 등장한 개념이 마이크로서비스 아키텍처이다. 기존 모놀리틱 서버는 배정받은 역할이 너무나도 크기 때문에 기동시키기에는 사용하는 자원에 부담이 크다.
또한 확장을 고려할 필요없는 내용을 포함해서도 확장되기 때문에 자원을 효율적으로 사용하지 못하게 된다.
이 내용을 그림으로 표현할 수 있는데 아래와 같다.

현재 어떤 이벤트로 인해서 결제에 대한 API 요청이 폭증했다고 가정해보자
모놀리틱의 구성이라면 한 대의 서버로 감당이 안되기 때문에 기존 서버와 똑같은 내용을 가진 서버를 가져와 기동시켜야한다. 저 많은 API를 처리하기 위한 모놀리틱 서버의 스펙 비용은 약 1000만원이라고 해보자
마이크로서비스의 개념을 적용하면 어떻게 될까? 결제에 대한 API 요청이 폭증했으니 결제를 담당하는 마이크로서버만 확장하면 되지 않을까?
그림으로 표현하면 아래와 같다.

마이크로 서버의 스펙 비용은 각각 약 250만원이라고 하자
마이크로서비스로 시스템을 초기부터 운영하려면 초기 비용은 많이 들 수 있다. 또한 이를 유지보수하는 인적/기술적인 비용도 만만치않긴하다.
하지만 지금 상황에서 결제 API에 대한 서버를 늘릴 때는 2대를 추가로 늘려도 모놀리틱의 절반 가격인 500만원으로 요청을 더 원활하게 받아낼 수 있게 된다.
비용이 구체적이고 현실적인 예시는 아닐 수 있지만 이렇게 자원을 늘리고 줄이는 아키텍처가 한정된 자원을 효율적으로 쓰이는 것에 장점이 있다고 판단하여 많은 서비스들이 적용하고 있다.
마이크로서비스 핵심 개념 6가지
1. 독립적으로 배포할 수 있어야한다.
약 6가지 핵심 개념 중 가장 중요한 개념이다. 이 외의 개념이 이 개념을 충족시키기위해서 존재한다고 볼 수 있을 정도이다.
다른 마이크로서비스를 배포하지 않고 마이크로서비스를 배포/변경할 수 있어야한다.
이 개념을 충족시키기 위해 마이크로서비스간 결합도/의존도를 낮춰야한다. 서비스간에 잘 정의되고 안정된 명세가 필요하다.
2. 비즈니스 도메인을 중심으로 모델링 해야한다.
도메인을 기준으로하여 서비스 경계를 정의해야한다.
- 즉, 한 마이크로서비스가 기능에 필요한 전체를 구현해야한다는 것이다.
- 이렇게 하면 새 기능 출시가 쉬워지고 다른 방식으로 마이크로서비스를 재조합하기 유용해진다.
한 기능의 구현이 여러 마이크로서비스에 걸쳐있으면 기능 출시 시 비용이 올라간다.
- 예를 들어 글쓰기 기능을 새로 만든다고 했을 때, 약 10개의 마이크로서비스와 상호작용을 해야한다고 가정해보자
- 그렇다면 10개의 마이크로서비스와 통신하는 내용을 작성하게 된다.
- 각 마이크로서비스를 담당하는 팀과의 커뮤니케이션, 서비스 통신 순서 관리, 예외처리에 대한 내용 등 구현 비용이 크게 늘어나게 된다.
- 그렇다면 10개의 마이크로서비스와 통신하는 내용을 작성하게 된다.
따라서 여러 서비스에 걸친 변경을 최소화해야한다.
3. 자신의 상태를 가져야한다.
마이크로서비스는 DB 혹은 데이터를 공유하지 않아야한다.
- 다른 마이크로서비스가 갖고 있는 데이터에 접근해야 하면 DB에 직접 접근하지 않고 API등을 통해서 접근해야한다.
- 데이터를 공유하지 않는다 –> 구현을 숨긴다 –> 결합도를 낮춘다.
4. 마이크로서비스를 다룰 수 있는 역량을 고려해야한다.
마이크로서비스를 설계할 때 주의할 점으로 아래와 같은 말이 있다고한다.
1
내 머리가 이해할 수 있을 정도의 크기를 가져야한다. (James Lewis)
하지만 위의 주의점은 상황에 따라 다를 수 밖에 없다.
–> 오랫동안 해당 서비스에 몸을 담은 사람 vs 신규 입시자
–> 스타트업 vs 대기업
이렇게 마이크로서비스를 다루는 대상마다 적용되는 범위가 달라질 수 밖에 없다.
따라서 마이크로서비스의 크기라는 용어보다는 다음 두 가지의 구체화에 대한 내용에 집중하는 것이 좋다.
- 얼마나 많은 마이크로서비스를 다룰 수 있는가?
- 마이크로서비스가 증가하면 복잡도가 증가하며 새 기술을 습득해야하는 가능성이 크다.
- 마이크로서비스 경계를 정의해야한다.
- 실타래가 복잡하게 얽히지 않도록 해야한다.
5. 마이크로서비스는 유연해야한다.
지금 더 비용을 들여 미래에 유연해질 수 있는 옵션을 구매해야한다. (여기서 옵션이란 하드웨어 스펙이 아닌 기술과 확장 가능성인 인적/기술적 비용을 가리킨다.)
아직 벌어지지 않은 미래에 너무 많은 옵션을 구매하는 것은 오버 엔지니어링이 될 가능성이 크다.
따라서 점진적으로 마이크로서비스로 전환해야하며 이 과정에서도 과하지 않게 설계해야한다.
6. 아키텍처와 조직을 맞춰야한다.
조직 간 이관이나 사일로(부서 이기주의 현상)를 줄여야한다.
아키텍처의 구조는 조직의 구조를 따르게 되어있다. (조직도 생태계를 반영할 수 밖에 없음)
기존 프론트 팀, 백엔드 팀, DB 팀과 같이 조직을 큰 단위로 구성했다면 고객 팀, 구매 팀등으로 세분화하여 여러 포지션을 한 조직에 모아 줄이는 것이 적절하다.
이렇게하면 각 담당한 도메인에 대한 응집도를 높일 수 있어 비즈니스 도메인에 집중할 수 있는 장점이 있다.
비즈니스 도메인을 중심으로 모델링 하기
왜 도메인을 중심으로 모델링을 해야하는가?
위에서 살펴본 마이크로서비스 핵심 개념 2번을 다시 떠올려보자
1
2
3
4
5
6
7
8
9
10
11
12
**도메인을 기준으로하여 서비스 경계를 정의해야한다.**
- 즉, 한 마이크로서비스가 기능에 필요한 전체를 구현해야한다는 것이다.
- 이렇게 하면 새 기능 출시가 쉬워지고 다른 방식으로 마이크로서비스를 재조합하기 유용해진다.
한 기능의 구현이 여러 마이크로서비스에 걸쳐있으면 기능 출시 시 비용이 올라간다.
- 예를 들어 글쓰기 기능을 새로 만든다고 했을 때, 약 10개의 마이크로서비스와 상호작용을 해야한다고 가정해보자
- 그렇다면 10개의 마이크로서비스와 통신하는 내용을 작성하게 된다.
- 각 마이크로서비스를 담당하는 팀과의 커뮤니케이션, 서비스 통신 순서 관리, 예외처리에 대한 내용 등 구현 비용이 크게 늘어나게 된다.
따라서 여러 서비스에 걸친 변경을 최소화해야한다.
도메인을 기준으로 설계를 한다면 유연한 시스템을 구축할 수 있다는 점이 있다고 했다.
그렇다면 도메인을 중심으로 설계하는 방법을 알아보는게 좋겠다.
1. CQRS 패턴
Command(Create, Update, Delete)와 Query(Read)를 분리하는 것이 도메인 중심 설계의 기초가 될 수도 있다.
- Command는 시스템의 데이터를 변경하는 행위를 가리킨다.
- 주문 취소, 배송 완료 등
- Query는 시스템의 데이터를 조회하는 행위를 가리킨다.
- 주문 목록 조회 등
CQRS는 Responsibility Segregation (책임 분리)라는 중요 개념에 의해 탄생했다.
- 책임은 구성 요소의 역할을 의미한다.
- 구성 요소(모델)는 아래 요소들을 가리킨다.
- 클래스, 함수, 모듈, 패키지, 웹서버, DB 등
- 구성 요소(모델)는 아래 요소들을 가리킨다.
이 요소들을 적절하게 분리하는 것이 권장된다.
- Command 역할을 수행하는 구성요소
- Query 역할을 수행하는 구성 요소를 나누는 것이 CQRS이다.
코드만 나누는 것이 아니라 구현 방법, DB, 프로세스를 나누기도 한다. 중요한 점은 변경하는 구성요소, 조회하는 구성요소를 나누는 것이다.

위와 같이 표현할 수 있겠다. 그런데 이 방식이 굳이 필요한 이유가 무엇일까?
Command에서 사용되는 Member와 Query에 사용되는 MemberData는 무슨 차이가 있을까?
단일 모델의 단일 책임 원칙 위반

위 그림처럼 마지막 로그인에 대한 기록, 최근 주문 일자에 대한 기록, 회원 이름 변경 기능 추가가 추가되었다고 했을 때 유저 테이블에서 이 모든 내용을 담도록 했다.
적절하게 속성을 부여한 것처럼 볼 수도 있지만 유저에 부여된 역할/책임이 모호해졌다. 즉, 유저 객체가 하는 일이 너무 많다는 것이다.
이렇게 하나의 객체에 너무 많은 역할과 책임을 부여하면 유지보수성이 상당히 떨어지게 된다.
정리하자면, 단순 유저를 조회하는 API가 있을 때, 유저의 실질적인 정보 이외의 실제 조회에 필요없는 내부 관리용 데이터마저도 사용하게 된다는 것이 문제점이다.
실제 코드로 CQRS 모델을 분리해보기
명령 모델은 우리가 단일 모델로 작성해오던 그 모델을 생각해도된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
@Table(name = "user")
@Entity
class UserEntity(
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
val id: Long = 0L,
@Column(name = "oauth_token_payload", nullable = true, length = 255)
var oauthTokenPayload: String?,
@Column(name = "fcm_token_payload", nullable = true, length = 255)
var fcmTokenPayload: String?,
@Embedded
var nickname: Nickname
) : BaseEntity()
조회 모델은 조회 요구사항에 맞게 만들어낸 모델들이라고 생각하면 된다. 이 때 각 모델을 결합한 비정규화된 데이터를 가지고 있는다.
1
2
3
4
class UserRetrieveModel(
var id: Long,
var nickname: Nickname,
)
1
2
3
4
5
6
7
class UserPostRetrieveModel(
var userId: Long,
var userNickname: Nickname,
var postId: Long,
var postTitle: String,
var postContent: String,
)
1
2
3
4
5
6
7
8
class UserOrderRetrieveModel(
var userId: Long,
var userNickname: Nickname,
var orderId: Long,
var orderStoreId: Long,
var orderStoreName: String,
var orderDateTime: LocalDateTime
)
이렇게 개발 공수도 많이 들어가는 명령/조회 모델을 분리하면 얻는 이점은 무엇일까?
각 조회 모델에 대한 최적화를 이루어낼 수 있다.
웬만한 서비스에서는 상대적으로 조회에 대한 요청이 많을 수 밖에 없다. 또한 사용자에게 가장 먼저 제공하는 기능도 조회인 경우가 많다.
각 조회 모델에 대한 캐시를 따로 관리하여 조회 성능에 대한 최적화를 적용할 수도 있다.
아래 그림이 그 예시이다.
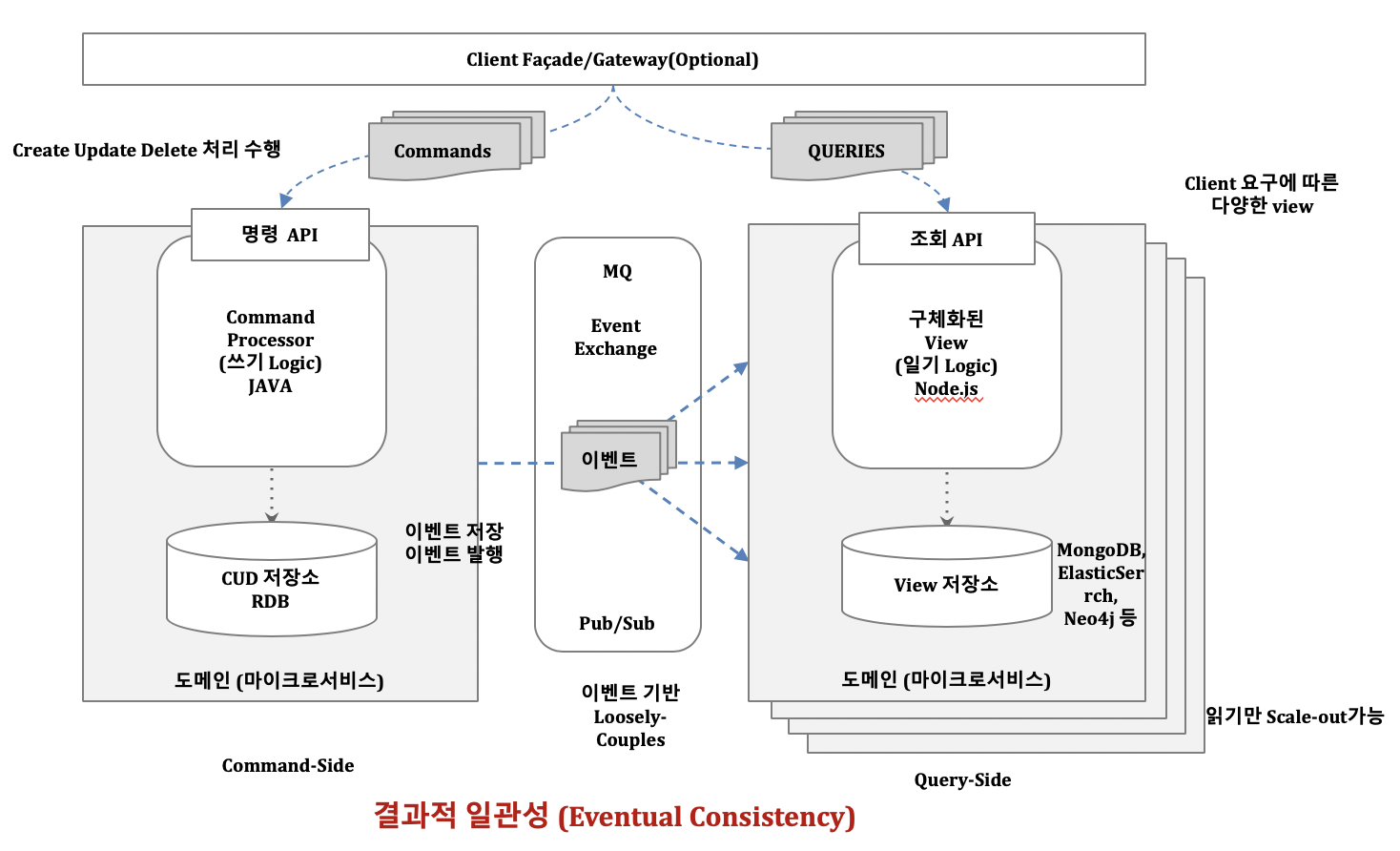
명령 측면 마이크로서비스는 입력, 수정, 삭제(Create, Update, Delete) 처리를 수행하고 저장소로는 쓰기에 최적화된 관계형 데이터베이스를 사용한다.
쿼리 측면의 마이크로서비스는 조회 성능이 높은 몽고디비(Mongo DB)나 엘라스틱서치(ElasticSearch)와 같은 NO-SQl DB를 사용한다. 그리고 조회서비스는 사용량이 많기 때문에 스케일 아웃하여 인스턴스를 증가시켜 놓을 수 있다.
그런데 이런 구조에서는 명령 측면 서비스가 사용됨에 따라 조회 측면 서비스와의 데이터 일관성이 깨지게 된다.
따라서 이때 데이터 일관성 유지를 위한 이벤트 메시지 주도 아키텍처가 등장한다. 쓰기 서비스는 저장소에 데이터를 쓰면서 저장한 내역이 담긴 이벤트를 발생시켜서 메시지브로커에 전달한다. 조회 서비스는 이러한 메시지 브로커의 이벤트를 구독하고 있다가 이벤트 데이터를 가져와 자신의 데이터를 최신 상태로 동기화 시켜준다.
물론 명령 측면 서비스에 데이터가 들어간 즉시 조회 측면 서비스의 데이터가 일치할 수 없고 시간적 간격이 있을 수 있지만 어느 시점이 되면 결과적으로 일치하게 된다. 앞서 말 한 결과적 일관성을(Eventual Consistency)추구하는 것이다.