ElasticSearch, 형태소 분석기 적용
참고 자료
ElasticSearch 개요
- ELK Stack의 E를 담당한다.
E:ElasticSearch로 JSON 기반의 저장소 및 검색엔진을 담당한다.L:Logstash로 Input Data, 데이터 변환을 수행하고 Stash하는 역할을 담당한다.K:Kibana로 UI DashBoard, Widgets/Visualization을 담당한다.- LogStash –> Provide Data –> ElasticSearch –> Visualization –> Kibana
- JSON을 기반으로한 데이터 저장소이다.
- RESTful API를 기반으로 한다.
- Logs, Metrics, Application Trace Data를 다루기 위한 목적이다.
ElasticSearch 구성요소의 용어
| ElasticSearch | 의미 | RDBMS |
|---|---|---|
인덱스 | 문서(데이터)들의 모음을 가리킨다. | 데이터베이스 |
샤드 | 인덱스를 분할한 것을 가리킨다. 엘라스틱서치는 대량의 데이터를 처리하고 분산 저장하기 위해 인덱스를 여러 샤드로 분할한다. 각 샤드는 별도의 노드로 저장되며 병렬로 검색/처리 작업을 수행할 수 있다. | 파티션 |
타입 | 7.0버전 부터는 사라진 개념이다. 테이블 없이 여러 유형의 데이터를 구분하기 위해 필드를 활용한다. | 테이블 |
문서 | 엘라스틱서치 내에서 검색/색인화/분석의 대상의 기본 데이터 단위이다. 일반적으로 JSON형식으로 표현하여 유연한 구조로 데이터를 표현할 수 있다. (블로그 게시물 문서 –> 제목, 내용, 작성자를 필드로 가진다.) | 행 |
필드 | 문서의 특정 부분으로, 각 필드는 해당하는 데이터 유형을 정의할 수 있다. | 열 |
QueryDSL | 엘라스틱서치에서 쿼리를 작성하기 위한 DSL이다. 쿼리 형식을 JSON형식으로 작성하여 검색 요청을 전달할 수 있다. | SQL |
ElasticSearch 메서드의 용어
| ElasticSearch(HTTP) | RDBMS(SQL) |
|---|---|
| GET | SELECT |
| PUT | INSERT |
| POST | UPDATE, SELECT |
| DELETE | DELETE |
| HEAD (인덱스 정보 확인) |
ElasticSearch의 구성요소
Apache Lucene라이브러리를 기반으로 동작한다. Lucene은 검색 엔진 라이브러리로 텍스트 전문을 탐색하여 역 인덱스로 분석/변환하는 기능을 가지고 있다.
Lucene
Lucene은 사용자가 텍스트 데이터(Word 및 PDF 문서, 이메일, 웹 페이지 등)를 색인화 할 수 있는 라이브러리이다.
Lucene이 수행하는 단계는 다음과 같은 두 가지가 있다.
검색하려는 문서의 역 인덱스를 만든다.
구문 분석 쿼리, 인덱스 탐색 후 결과를 반환한다.

역 인덱스 개념
Lucene은 Inverted Index를 사용한다.
SQL 에서는 LIKE 검색이 INDEX 기능을 이용할 수 없다는 단점이 있어서, 그 문제를 극복하기 위해서 단어(Term)로 인덱싱을 하는 Inverted Index 방식이 고안되었다.
기존의 데이터베이스가 하나의 구분자(Primary Key)가 여러 필드를 지정하고 있었다면 Inverted Index에서는 하나의 값(Term)이 해당 Term이 들어간 document id를 지정하고 있다.
쉽게 설명하자면, 단어를 Key 사용하고 Value에는 그 단어를 포함한 Document의 번호가 들어있는 구조이다.
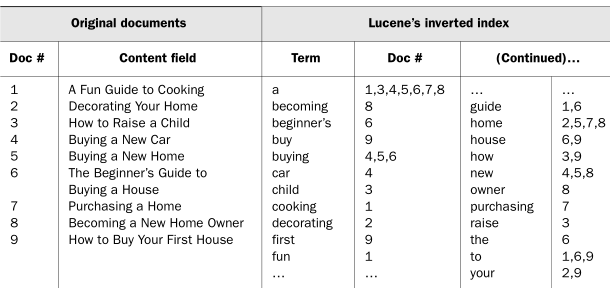
위 그림에서 how to purchasing guide라는 문자열을 검색한다면
how,to,purchasing,guide라고 나눈 후 각 단어(용어(Term))에 해당하는 인덱스인
(3, 9), (1, 6, 9), (7), (1, 6)을 반환한다. 그리고 여기서 가장 많이 등장한 인덱스인 (6, 9)가 가장 유사한 결과물로 취급될 수 있다.
이 처럼 어떤 문장에 해당하는 단어(용어(Term))이 인덱싱 되어있기 때문에 탐색 속도가 매우 빠르다.
Lucene에서의 역 인덱스 (Analyzer, Write Index)
다양한 유형의 문서를 인덱싱하기 위해선 Lucene이 주어진 문서에서 테스트를 구문 분석할 수 있는 형식으로 추출할 수 있어야 한다.
이를 위해 Analyzer가 사용된다.
Analyzer는 텍스트 데이터를 필터링하고 정리한다. 텍스트 데이터는 아래와 같은 여러 단계를 거쳐 가공된다.
- 단어 추출
- 불용어 제거
- 단어를 소문자로 만들기
등의 과정을 통해 텍스트를 인덱스에 추가할 수 있는 토큰(단어 == 용어 == Term)으로 변환한다.(코드상에선 TokenStream을 반환한다.)
아래 그림은 추출된 텍스트 데이터를 바탕으로 기본 파일 시스템에 역 인덱스로 저장되는 인덱싱 프로세스를 나타낸다.
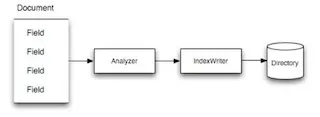
아래 그림은 특정 텍스트가 들어있는 Document와 불용어를 바탕으로 역 인덱스를 만들어내는 작업을 도식화 한 것이다.
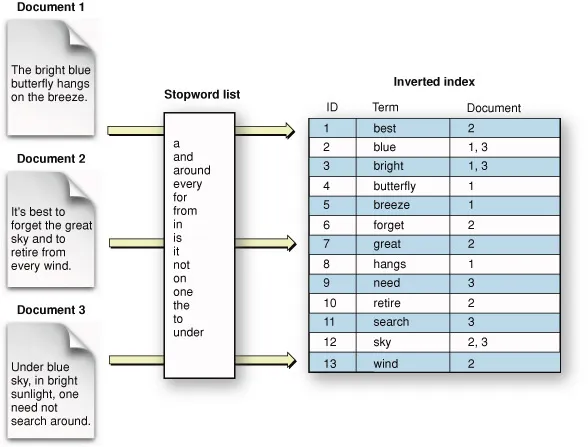
Lucene이 검색을 수행하는 과정
역 인덱스를 기반으로 구문을 분석하여 DB든 File System이든 Memeory든 Write를 했으면 그 내용을 바탕으로 검색을 수행할 수 있다.
이 때 인덱스의 모든 쿼리는 IndexSearcher를 통해 수행된다. 검색 하고자하는 내용이 주어지면 쿼리 구문을 분석할 QueryParser를 만들어 인덱스에서 결과를 검색한다.
결과는 문서 ID와 쿼리와 일치하는 결과의 신뢰도 점수(ScoreDocs)를 포함하는 TopDocs로 반환된다.
IndexSearcher
인덱스를 읽을 수 있는 액세스를 제공한다.
Query객체를 가져오고 TopDocs를 결과로 반환하는 여러 검색 메서드를 제공한다.
이 클래스는 인덱스 생성/업데이트에 사용되는 IndexWriter 클래스와 반대의 역할을 수행한다.
Term
검색의 기본 단위이다. 인덱싱에 사용되는 Field 객체의 반대의 역할을 수행한다.
인덱스를 생성할 때 특정 필드를 만들고 검색할 때 TermQuery의 용어를 사용한다.
필드 이름에서 값으로의 매핑을 포함한다.
Query
Lucene은 아래 유형의 쿼리를 비롯한 여러 유형의 쿼리를 제공한다. 각 쿼리 유형은 인덱스를 검색하는 고유한 방법을 가지고 있다.
TermQueryBooleanQueryPrefixQueryWildcardQueryPhraseQueryFuzzyQuery
QueryParser
사람이 읽을 수 있는 쿼리(예: “opower AND arlington”)를 검색에 사용할 수 있는 쿼리 개체로 구문 분석한다.
TopDocs
N개의 검색 결과에 대한 포인터를 위한 컨테이너이다. 각 TopDoc에는 문서 ID와 Confidence Score(검색 결과에 대한 적합도)가 포함되어있다.
Lucene의 일부를 사용해서 문장의 키워드를 추출하기 (Kotlin)
프로젝트를 진행하는 중 특정 뉴스 기사 내용을 키워드로 요약해야하는 요구사항을 해결하기 위해 Lucene을 사용하기로 했다.
자세한 설명은 주석으로 대체한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
import java.io.StringReader
import org.apache.lucene.analysis.ko.KoreanAnalyzer
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute
fun main() {
// 기사 내용
val content = "테스트 기사 내용입니다. 오늘 테스트를 수행했습니다."
// 키워드를 몇 개를 추출할 것인지?
val keywordCount = 4
// Lucene 분석기
val analyzer = KoreanAnalyzer()
// 불용어
val stopWords = setOf(
"은", "는", "이", "가", "을", "를", "과", "와", "에서", "으로", "에게", "으로부터", "에", "의"
)
// 단어 등장 횟수
val wordFrequencies = mutableMapOf<String, Int>()
// 뉴스 기사 내용을 문자 단위로 읽기 위한 StringReader
val contentStringReader = StringReader(content)
// 문자 단위로 읽은 내용을 담고있는 StringReader를 Lucene Token로 변환
val tokenStream = analyzer.tokenStream("text", contentStringReader)
val wordsInContent = tokenStream.addAttribute(CharTermAttribute::class.java)
// 공식문서 스펙에 따라 Token.incrementToken()메서드를 실행하기 전 반드시 실행해야하는 메서드
tokenStream.reset()
// 토큰(단어) 순회
while (tokenStream.incrementToken()) {
val word = wordsInContent.toString()
// 순회하는 단어가 불용어가 아니고 2글자 이상의 단어라면 키워드 후보로 카운트한다.
if (word !in stopWords && word.length > 1) {
wordFrequencies[word] = wordFrequencies.getOrDefault(word, 0) + 1
}
}
tokenStream.end()
tokenStream.close()
// 추출된 키워드를 키워드의 갯수에 맞게 반환한다.
val sortedKeywords = wordFrequencies.entries
.sortedByDescending { it.value }
.take(keywordCount).map { it.key }
.joinToString { ", " }
.replace("[", "")
.replace("]", "")
println("sortedKeywords = ${sortedKeywords}")
}
Lucene을 사용하지 않은 문자열 처리와 비교하기
Lucene을 사용하기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
fun main() {
val content =
"경남 사천 공군 3훈련비행단에서 열린 제1차 한-폴란드 국방·방산협력 공동위원회 [국방부 제공]◆ 한-폴란드 '국방·방산 협력 공동위' 첫 개최‥국방·방산 교류 대폭 확대키로 국방부가 K-방산의 큰손으로 급부상한 폴란드의 부총리 겸 국방장관 일행 방한을 계기로, 국산 무기 체계의 우수성을 적극 홍보하는 한편, 군사분야 교류를 대폭 확대하기로 했습니다. 이종섭 국방부 장관은 오늘 방한 중인 마리우시 브와슈차크 폴란드 부총리 겸 국방부 장관과 경남 사천 제3훈련비행단에서 '제1차 한·폴란드 국방 및 방산 협력 공동위원회'를 개최했습니다. 이 장관은 회담에서 " 방산 협력 분야에서 쌓아온 신뢰 관계를 바탕으로 후속 계약과 폴란드 현지 생산 등 진전된 방산 협력 추진이 논의 중 "이라고 말했습니다. 이어 " 양국 간 장기적 . 호폐적 방산 협력 여건이 지속적으로 마련될 수 있도록 지지해달라 "고 당부했습니다. 이 자리에서 양측은 양국 군 교차 방문 및 군사훈련 실시, 한국 내 무기체계 운용 교육 및 훈련 등 군사분야에서의 협력 범위를 점진적으로 확대하기로 합의했습니다. ◆ 폴란드 수출형 FA-50 1호기 출고식 참석.." 우정은 술과 같은 것, 묵을수록 좋다" 공동위에 앞서 두 장관은 이날 오전 경남 사천 한국항공우주산업 KAI 격납고에서 폴란드 수출용으로 제작된 FA-50FG 1호기 출고식 행사에 참석했습니다. KAI는 지난해 9월 경공격기 FA-50 48대 수출 계약을 체결했는데, 우선적으로 납품하기로 한 12대 중 첫 물량을 불과 8개월만에 출고한 겁니다. 이종섭 장관은 축사를 통해 "양국은 지난해 FA-50 외에도 K2전차와 K-9자주포 그리고 다연장로켓 '천무' 등 총 124억불, 우리돈으로 16조1천7백억원의 1차 이행 계약을 체결했고, 이 가운데 전차와 자주포는 이미 지난해 초도 물량이 성공적으로 폴란드에 인도돼 시범사격 훈련까지 실시했다"고 말했습니다. 그러면서 "양국의 방산협력은 짧은 시간 안에 성공적으로 추진될 수 있었던 것은 우리 기업의 뛰어난 기술력과 생산 역량 뿐 아니라, 양국 간 신뢰와 폴란드 측의 결단 덕분"이라며 "우정은 술과 같은 것으로 묵을수록 좋다는 폴란드 속담처럼 오늘 행사를 계기로 양국의 우정과 협력관계가 더욱 발전하길 기대한다"고 말했습니다. 이에 브와슈차크 장관은 "FA-50GF의 빠른 출고 덕분에 폴란드 전력의 조기 보강 및 현대화가 가능해졌다"며 "FA-50GF가 폴란드의 영공을 비행하는 날을 기대한다"고 말했습니다. KAI는 폴란드와 계약한 48대 중 나머지 36대는 폴란드 공군의 요구도를 반영해 현존 최고 사양의 FA-50 성능개량 버전인 FA-50PL 형상으로 2025년 하반기부터 2028년까지 납품할 계획입니다. ◆ '합동화력 격멸훈련'에 초청..국산 무기 우수성 '실전적' 홍보 '국방 및 방산 협력 공동위'를 마친 브와슈차크 장관 일행은 곧바로 경기도 포천 승진훈련장으로 이동해 역대 최대 규모로 열리고 있는 '연합합동화력격멸훈련'을 참관했습니다. 이 장관이 직접 주관한 이날 훈련에는 K2 전차와 K21 장갑차 등 기동전력 외에도, 천무·구룡·K9 자주포 등 포병 전력이 대거 동원됐는데, 모두 세계 시장에서 이미 압도적인 성능을 입증받은 국산 무기 체계들입니다. 이 외에도, FA-50과 KF-16, F-15K 전투기와 코브라·아파치 등 우리 군이 운용중인 공중 전력도 함께 투입해, 합동 화력의 위용을 선보였습니다. 국방부 관계자는 "국산 무기 체계가 실전에서 다른 전력과 합동으로 어떻게 운용되는지를 보다 실감나게 보여주기 위해 폴란드측 인사들을 초청했다"고 말했습니다. 브와슈차크 장관은 훈련을 '직관'하는 동안 연신 "대단하다. 놀랍다"며 감탄을 쏟아낸 것으로 전해졌습니다. 현장에서는 국산 차륜형 장갑차와 무인 전투체계, 천무와 천궁2 무기 체계에 대한 군 작전요원들의 별도 브리핑도 진행됐는데, 브와슈차크 장관이 무기 체계의 제원 등에 관해 질문하는 등 큰 관심을 보였다고 군 관계자는 전했습니다."
val keywordCount = 4
val analyzer = KoreanAnalyzer()
val stopWords = setOf(
"은", "는", "이", "가", "을", "를", "과", "와", "에서", "으로", "에게", "으로부터", "에", "의"
)
val wordFrequencies = mutableMapOf<String, Int>()
val contentStringReader = StringReader(content)
val tokenStream = analyzer.tokenStream("text", contentStringReader)
val wordInContent = tokenStream.addAttribute(CharTermAttribute::class.java)
tokenStream.reset()
while (tokenStream.incrementToken()) {
val word = wordInContent.toString()
if (word !in stopWords && word.length > 1) {
wordFrequencies[word] = wordFrequencies.getOrDefault(word, 0) + 1
}
}
tokenStream.end()
tokenStream.close()
val sortedKeywords = wordFrequencies.entries.sortedByDescending { it.value }
val topKeywords = sortedKeywords.take(keywordCount).map { it.key }
println(
topKeywords.joinToString(", ")
.replace("[", "")
.replace("]", "")
)
}
출력 결과
폴란드, 국방, 장관, 훈련
수행 시간
2137 milli
Lucene없이 문자열 처리하기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
fun main1() {
val content =
"경남 사천 공군 3훈련비행단에서 열린 제1차 한-폴란드 국방·방산협력 공동위원회 [국방부 제공]◆ 한-폴란드 '국방·방산 협력 공동위' 첫 개최‥국방·방산 교류 대폭 확대키로 국방부가 K-방산의 큰손으로 급부상한 폴란드의 부총리 겸 국방장관 일행 방한을 계기로, 국산 무기 체계의 우수성을 적극 홍보하는 한편, 군사분야 교류를 대폭 확대하기로 했습니다. 이종섭 국방부 장관은 오늘 방한 중인 마리우시 브와슈차크 폴란드 부총리 겸 국방부 장관과 경남 사천 제3훈련비행단에서 '제1차 한·폴란드 국방 및 방산 협력 공동위원회'를 개최했습니다. 이 장관은 회담에서 " 방산 협력 분야에서 쌓아온 신뢰 관계를 바탕으로 후속 계약과 폴란드 현지 생산 등 진전된 방산 협력 추진이 논의 중 "이라고 말했습니다. 이어 " 양국 간 장기적 . 호폐적 방산 협력 여건이 지속적으로 마련될 수 있도록 지지해달라 "고 당부했습니다. 이 자리에서 양측은 양국 군 교차 방문 및 군사훈련 실시, 한국 내 무기체계 운용 교육 및 훈련 등 군사분야에서의 협력 범위를 점진적으로 확대하기로 합의했습니다. ◆ 폴란드 수출형 FA-50 1호기 출고식 참석.." 우정은 술과 같은 것, 묵을수록 좋다" 공동위에 앞서 두 장관은 이날 오전 경남 사천 한국항공우주산업 KAI 격납고에서 폴란드 수출용으로 제작된 FA-50FG 1호기 출고식 행사에 참석했습니다. KAI는 지난해 9월 경공격기 FA-50 48대 수출 계약을 체결했는데, 우선적으로 납품하기로 한 12대 중 첫 물량을 불과 8개월만에 출고한 겁니다. 이종섭 장관은 축사를 통해 "양국은 지난해 FA-50 외에도 K2전차와 K-9자주포 그리고 다연장로켓 '천무' 등 총 124억불, 우리돈으로 16조1천7백억원의 1차 이행 계약을 체결했고, 이 가운데 전차와 자주포는 이미 지난해 초도 물량이 성공적으로 폴란드에 인도돼 시범사격 훈련까지 실시했다"고 말했습니다. 그러면서 "양국의 방산협력은 짧은 시간 안에 성공적으로 추진될 수 있었던 것은 우리 기업의 뛰어난 기술력과 생산 역량 뿐 아니라, 양국 간 신뢰와 폴란드 측의 결단 덕분"이라며 "우정은 술과 같은 것으로 묵을수록 좋다는 폴란드 속담처럼 오늘 행사를 계기로 양국의 우정과 협력관계가 더욱 발전하길 기대한다"고 말했습니다. 이에 브와슈차크 장관은 "FA-50GF의 빠른 출고 덕분에 폴란드 전력의 조기 보강 및 현대화가 가능해졌다"며 "FA-50GF가 폴란드의 영공을 비행하는 날을 기대한다"고 말했습니다. KAI는 폴란드와 계약한 48대 중 나머지 36대는 폴란드 공군의 요구도를 반영해 현존 최고 사양의 FA-50 성능개량 버전인 FA-50PL 형상으로 2025년 하반기부터 2028년까지 납품할 계획입니다. ◆ '합동화력 격멸훈련'에 초청..국산 무기 우수성 '실전적' 홍보 '국방 및 방산 협력 공동위'를 마친 브와슈차크 장관 일행은 곧바로 경기도 포천 승진훈련장으로 이동해 역대 최대 규모로 열리고 있는 '연합합동화력격멸훈련'을 참관했습니다. 이 장관이 직접 주관한 이날 훈련에는 K2 전차와 K21 장갑차 등 기동전력 외에도, 천무·구룡·K9 자주포 등 포병 전력이 대거 동원됐는데, 모두 세계 시장에서 이미 압도적인 성능을 입증받은 국산 무기 체계들입니다. 이 외에도, FA-50과 KF-16, F-15K 전투기와 코브라·아파치 등 우리 군이 운용중인 공중 전력도 함께 투입해, 합동 화력의 위용을 선보였습니다. 국방부 관계자는 "국산 무기 체계가 실전에서 다른 전력과 합동으로 어떻게 운용되는지를 보다 실감나게 보여주기 위해 폴란드측 인사들을 초청했다"고 말했습니다. 브와슈차크 장관은 훈련을 '직관'하는 동안 연신 "대단하다. 놀랍다"며 감탄을 쏟아낸 것으로 전해졌습니다. 현장에서는 국산 차륜형 장갑차와 무인 전투체계, 천무와 천궁2 무기 체계에 대한 군 작전요원들의 별도 브리핑도 진행됐는데, 브와슈차크 장관이 무기 체계의 제원 등에 관해 질문하는 등 큰 관심을 보였다고 군 관계자는 전했습니다."
val keywordCount = 4
val stopWords = setOf(
"은", "는", "이", "가", "을", "를", "과", "와", "에서", "으로", "에게", "으로부터", "에", "의"
)
val wordFrequencies = mutableMapOf<String, Int>()
val contentStringReader = StringReader(content)
val words = contentStringReader.readText().split(" ")
for (word in words) {
if ((word !in stopWords) && (word.length > 1)) {
wordFrequencies[word] = wordFrequencies.getOrDefault(word, 0) + 1
}
}
val sortedKeywords = wordFrequencies.entries.sortedByDescending { it.value }
val topKeywords = sortedKeywords.take(keywordCount).map { it.key }
println(
topKeywords.joinToString(", ")
.replace("[", "")
.replace("]", "")
)
}
출력 결과
폴란드, 협력, 무기, 장관은
수행 시간
113 milli
사실 Lucene에 대해서 리서칭하고 동작과정을 살펴본 결과 문서 검색이 아닌 키워드를 추출하는데에 굳이 Lucene을 써야하는가? 에 대한 생각이 들어서 작성해본 코드이다.
Lucene의 분석기 없이 키워드를 추출하는 로직을 사용하면 수행시간은 더 빠를 수 있으나 정확도가 다소 떨어지게 된다.
명사만 추출해오는 것이 아니라는 점과 그것에 연쇄되어 오직 명사만 해당한 내용에 대한 빈도수를 체크하는게 아니기 때문이다.
Lucene 한국어 분석기를 통해 추출해온 내용을 바탕으로 한다면 시간은 다소 더 소요되나 부가적인 품사 없이 명사로만 이루어진 키워드를 뽑아낼 수 있었다.
물론 Lucene없이 명사만 뽑아오도록 할 순 있겠지만 추가적인 리소스가 소요된다는 점이 고려되었기도 하고 생산성적인 측면에서 Lucene의 분석기를 사용하여 처리하였다.
ElasticSearch 인덱싱 속도 개선의 12가지 방법
1. 벌크 요청 사용하기
일반적으로 매번 인덱스에 어떤 작업을 요청하는 것 보다는 대량의 내용을 인덱스에 요청하는 것이 적합하다.
벌크 요청의 크기를 최적화 하기 위해 단일 노드, 단일 샤드 환경에서의 벤치마크가 필요하다.
처음에는 100개의 요청을 만들고 수행, 그리고 점차 200 -> 400 2배씩 늘려가며 벌크 요청의 성능을 측정하자.
요청-응답 간의 속도가 느려지기 시작하면 벌크 요청의 최적의 크기에 도달한 것으로 판단하면 된다. 만약 비슷한 수치를 기록한 케이스에는 문서양이 조금 더 적은 케이스로 적용하는 것이 더 좋다.
너무 큰 벌크 요청이 동시에 전송되면 클러스터에 메모리를 많이 차지하게 되므로 요청 당 수십MB를 넘지 않도록 주의해야한다.
2. 여러 Workers/Threads를 사용해서 Elastic Search로 데이터 전송하기
단일 쓰레드로 벌크 요청하는 것은 ElasticSearch Cluster의 Indexing용량을 극대화해서 사용할 수 없다.
클러스터의 모든 리소스를 사용하려면 여러 쓰레드나 프로세스에서 데이터를 전송하여 fsync비용을 줄일 수 있다.
벌크 요청의 크기를 조정하는 것과 마찬가지로 벤치마크를 통해 최적의 Workers의 수를 알 수 있다.
I/O, CPU가 포화상태가 되기 전까지 수를 점진적으로 늘려가며 그 설정을 찾아내면 된다.
##